
فهرست مطالب
- مقدمه
- آزمون t چیست؟
- کاربردهای آزمون :t چه زمانی از آن استفاده کنیم؟
- انواع آزمون t: سه نوع اصلی
- راهنمای سریع انتخاب نوع آزمون t
- جدول مقایسه انواع آزمون t
- فرضهای لازم برای استفاده از آزمون t
- چه زمانی آزمون t مناسب نیست؟
- مثالهای کاربردی
- اشتباهات رایج در استفاده از آزمون t
- جمعبندی
- سوالات متداول
مقدمه
اگر تا حالا برای پایاننامه یا یک پروژهی تحقیقاتی به دادههای آماریتان نگاه کردهاید و از خودتان پرسیدهاید «آیا این دو میانگین واقعاً با هم فرق دارند یا این تفاوت فقط یک اتفاق است؟»، آزمون t دقیقاً همین سؤال را برایتان جواب میدهد.
به زبان ساده، آزمون t یکی از پرکاربردترین روشهای آمار استنباطی است که برای مقایسهی میانگین دو گروه (یا مقایسهی میانگین یک گروه با یک عدد ثابت) استفاده میشود. مثلاً فرض کنید میخواهید بدانید نمرهی دانشجویانی که صبح امتحان دادهاند با نمرهی دانشجویانی که عصر امتحان دادهاند تفاوت معناداری دارد یا خیر؛ یا میخواهید فشار خون بیماران را قبل و بعد از یک دارو مقایسه کنید. در همهی این موارد، آزمون tابزاری است که به شما میگوید این تفاوت «واقعی» است یا صرفاً ناشی از شانس.
کاربرد آزمون t در رشتههای مختلف:
روانشناسی و علوم تربیتی
پزشکی و پرستاری
مدیریت و کسبوکار
علوم اجتماعی و جامعهشناسی
به همین دلیل، آزمون t یکی از اولین آزمونهایی است که هر دانشجوی پایاننامه باید با آن آشنا شود. در این مقاله، قدمبهقدم یاد میگیرید آزمون t چیست، چه انواعی دارد، چه زمانی باید از آن استفاده کنید.
آزمون t چیست؟
آزمون t یک آزمون آماری پارامتریک است که برای مقایسهی میانگین دو گروه یا مقایسهی میانگین یک گروه با یک مقدار مشخص طراحی شده است. این آزمون بر پایهی توزیعt (که به آن توزیع تی استیودنت (student t distrubation) هم میگویند) بنا شده است. این توزیع شکلی شبیه به توزیع نرمال دارد، اما دنبالههای پهنتری دارد و همین موضوع آن را برای حجم نمونههای کوچک مناسبتر میکند
سؤالی که اغلب دانشجویان میپرسند این است: تفاوت آزمون t با z-test چیست؟ پاسخ کوتاه این است: وقتی واریانس جامعه را نمیدانیم و حجم نمونه کوچک است (معمولاً کمتر از ۳۰ نفر)، از آزمون t استفاده میکنیم؛ اما وقتی واریانس جامعه مشخص است یا حجم نمونه بسیار بزرگ است، z-test گزینهی مناسبتری است. در عمل پژوهشی، چون واریانس جامعه تقریباً همیشه نامعلوم است، آزمون t کاربرد بسیار بیشتری نسبت به z-test دارد.
اما چرا اسمش «t» است؟ این حرف به نام مستعار آماردانی برمیگردد که این روش را در اوایل قرن بیستم معرفی کرد؛ او مقالهاش را با نام مستعار «Student» منتشر کرد و حرف t هم برای نامگذاری آمارهی آزمون انتخاب شد.
کاربردهای آزمون :t چه زمانی از آن استفاده کنیم؟
آزمون t زمانی به کار میرود که دادهی شما کمّی (پیوسته) باشد و بخواهید میانگین دو گروه را با هم، یا میانگین یک گروه را با یک عدد مشخص، مقایسه کنید. چند مثال واقعی از کاربرد آزمون t در پژوهشها:
مقایسهی میانگین اضطراب امتحان در دختران و پسران یک مدرسه (آزمون تی مستقل)
بررسی اینکه آیا میانگین نمرهی ریاضی یک کلاس با میانگین کشوری (مثلاً ۱۵) تفاوت دارد یا نه (آزمون تی تک نمونه ای)
مقایسهی فشار خون بیماران قبل و بعد از مصرف یک داروی جدید (آزمون تی زوجی)
بهطور خلاصه، هر زمان که سؤال پژوهشی شما با عبارتهایی مثل «آیا بین... تفاوت معناداری وجود دارد» یا «آیا میانگین... قبل و بعد از... تغییر کرده» شروع شود، احتمالاً به آزمون t نیاز دارید.
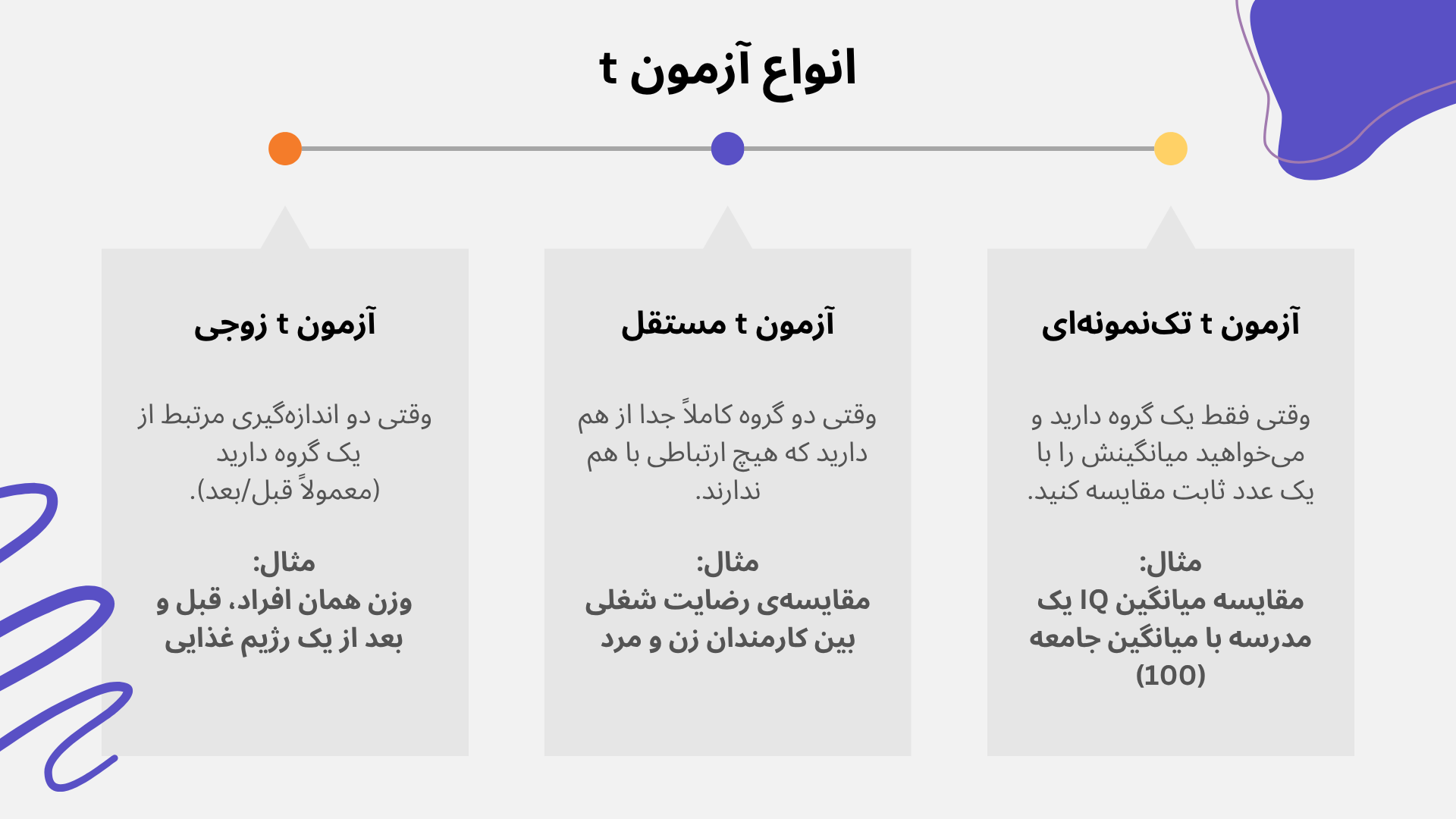
انواع آزمون :t سه نوع اصلی
آزمون t در آمار به سه دستهی اصلی تقسیم میشود که هرکدام برای یک نوع داده و سؤال پژوهشی خاص طراحی شدهاند. شناخت دقیق تفاوت این سه نوع، مهمترین قدم برای انتخاب درست آزمون است.
۱. آزمون t تکنمونهای (One-Sample t-test)
این نوع آزمون زمانی استفاده میشود که میخواهید میانگین یک گروه را با یک عدد مشخص و از پیش تعیینشده (مثل یک استاندارد، نُرم یا مقدار جامعه) مقایسه کنید.
فرضیهها:
:H0میانگین جامعه برابر با مقدار مشخص است (μ = μ0)
H1: میانگین جامعه با آن مقدار تفاوت دارد (μ ≠ μ0)
مثال:
فرض کنید میانگین نمرهی هوش (IQ) در جامعه ۱۰۰ است. شما میخواهید بدانید آیا میانگین IQ دانشآموزان یک مدرسهی خاص با این عدد تفاوت معناداری دارد یا نه. در این حالت، فقط یک گروه (دانشآموزان مدرسه) دارید که میانگینش را با عدد ثابت ۱۰۰ مقایسه میکنید.
۲. آزمون t مستقل یا گروههای مستقل (Independent-Samples t-test)
این نوع، پرکاربردترین نوع آزمون t است و برای مقایسهی میانگین دو گروه کاملاً جدا و بدون ارتباط با هم استفاده میشود؛ یعنی افراد گروه اول هیچ ارتباطی با افراد گروه دوم ندارند.
فرضیهها:
H0 : میانگین دو گروه برابر است (μ1 = μ2)
:H1 میانگین دو گروه با هم تفاوت دارد (μ1 ≠ μ2)
مثال:
مقایسهی میانگین رضایت شغلی بین کارمندان زن و مرد یک شرکت. این دو گروه (زن و مرد) کاملاً از هم مستقلاند و هیچ فرد مشترکی بین آنها وجود ندارد.
۳. آزمون t زوجی یا وابسته (Paired-Samples t-test)
این نوع زمانی استفاده میشود که دو مجموعه داده به هم وابسته یا مرتبط باشند؛ معمولاً وقتی از یک گروه واحد، دو بار اندازهگیری انجام میشود (مثلاً قبل و بعد از یک مداخله) یا وقتی افراد دو گروه بهصورت زوجی با هم جفت شدهاند.
فرضیهها:
:H0 میانگین تفاوت دو اندازهگیری صفر است (μd = 0)
:H1 میانگین تفاوت دو اندازهگیری صفر نیست (μd ≠ 0)
مثال:
اندازهگیری وزن ۳۰ نفر قبل از شروع یک برنامهی غذایی و دوباره اندازهگیری وزن همان ۳۰ نفر بعد از ۸ هفته. چون دادهها از همان افراد و در دو زمان مختلف جمعآوری شدهاند، باید از آزمون t زوجی استفاده شود.
راهنمای سریع انتخاب نوع آزمون t
برای اینکه در عمل گیج نشوید، میتوانید با پاسخ به ۳ سؤال زیر، بهسرعت نوع آزمون t مناسب را پیدا کنید:
سؤال کلیدی | اگر پاسخ «بله» است | اگر پاسخ «نه» است |
آیا فقط یک گروه دارید و میخواهید آن را با یک عدد ثابت مقایسه کنید؟ | آزمون t تکنمونهای | به سؤال بعدی بروید |
آیا دادههای دو گروه از همان افراد یا جفتهای مرتبط بهدست آمدهاند (مثل قبل/بعد)؟ | آزمون t زوجی | به سؤال بعدی بروید |
آیا دو گروه کاملاً مستقل و بدون ارتباط با هم دارید؟ | آزمون t مستقل | احتمالاً آزمون t مناسب نیست؛ گزینههای دیگر را بررسی کنید |
ویژگی | تکنمونهای | مستقل | زوجی |
تعداد گروه | ۱ گروه | ۲ گروه مستقل | ۲ اندازهگیری مرتبط (۱ گروه) |
نوع داده | کمّی (فاصلهای/نسبتی) | کمّی | کمّی |
مثال | مقایسهی میانگین IQ مدرسه با ۱۰۰ | مقایسهی رضایت شغلی زن/مرد | وزن قبل/بعد از رژیم |
فرض اصلی (H0) | μ = μ0 | μ1 = μ2 | μd = 0 |
پیشنیاز خاص | — | همگنی واریانسها (Levene) | — |
نام در SPSS | One-Sample T Test | Independent-Samples T Test | Paired-Samples T Test |
فرضهای لازم برای استفاده از آزمون t
پیش از اجرای هر آزمون t، باید مطمئن شوید دادههای شما چند پیشفرض اساسی را رعایت میکنند؛ در غیر این صورت نتیجهی آزمون قابل اعتماد نخواهد بود.
۱ .نرمال بودن توزیع دادهها :(Normality)
متغیر وابسته باید (تقریباً) دارای توزیع نرمال باشد. در SPSS با آزمون شاپیروویلک (برای نمونههای کوچک) یا کولوموگروف اسمیرنوف (برای نمونههای بزرگتر) و همچنین نگاه به نمودار هیستوگرام یا Q-Q Plot بررسی میشود.
۲ .مستقل بودن مشاهدات :(Independence of observations)
دادههای هر فرد باید مستقل از سایر افراد باشد؛ یعنی نمرهی یک فرد نباید روی نمرهی فرد دیگر اثر بگذارد. این پیشفرض معمولاً از طریق طراحی درست پژوهش (نه آزمون آماری) تأمین میشود.
۳ .مقیاس فاصلهای یا نسبتی بودن متغیر :(Scale/Interval-Ratio data)
متغیر وابسته باید کمّی باشد (مثل نمره، سن، وزن، درآمد)، نه رتبهای یا اسمی. اگر دادهی شما رتبهای است، باید به سراغ آزمونهای ناپارامتریک مثل ویلکاکسون یا من-ویتنی بروید.
۴ .همگنی واریانسها :(Homogeneity of Variances) —
فقط برای آزمون t مستقل واریانس دو گروه باید با هم تقریباً برابر باشد. در SPSS این پیشفرض بهصورت خودکار با آزمون Levene بررسی میشود و در جدول خروجی نمایش داده میشود. اگر p-value آزمون Levene کمتر از 0/05 باشد، یعنی واریانسها برابر نیستند و باید از ردیف «Equal variances not assumed» در خروجی استفاده کنید.
۵ .عدم وجود دادههای پرت شدید :(No extreme outliers)
وجود چند دادهی پرت میتواند میانگین و نتیجهی آزمون را بهشدت تحت تأثیر قرار دهد. با نمودار Boxplot در SPSS میتوانید دادههای پرت را شناسایی کنید.
جدول زیر خلاصهای از پیشفرضها و نحوهی بررسی هرکدام در SPSS است:
پیشفرض | نحوهی بررسی در SPSS |
نرمال بودن | شاپیرو ویلک / کولموگروف اسمیرنوف / Q-Q Plot |
مستقل بودن مشاهدات | طراحی پژوهش (نه آزمون آماری) |
مقیاس فاصلهای/نسبتی | بررسی نوع متغیر در Variable View |
همگنی واریانسها | آزمون لون (levene)- (در خروجی Independent t خودکار است) |
نبود دادهی پرت | نمودار Boxplot |
چه زمانی آزمون t مناسب نیست؟
با وجود کاربرد گسترده، آزمون t همیشه گزینهی درستی نیست. در موارد زیر بهتر است به سراغ روشهای دیگر بروید:
بیش از دو گروه دارید:
اگر میخواهید میانگین سه گروه یا بیشتر را مقایسه کنید (مثلاً سه روش تدریس)، آزمون t مناسب نیست و باید از تحلیل واریانس یکطرفه (One-Way ANOVA) استفاده کنید. استفادهی پشتسرهم از چند آزمون t برای این منظور، خطای نوع اول را افزایش میدهد.
دادههای شما بهشدت غیرنرمال هستند:
اگر حجم نمونه کوچک است (مثلاً کمتر از ۳۰ نفر در هر گروه) و توزیع دادهها بهوضوح نرمال نیست، نتیجهی آزمون t قابل اعتماد نخواهد بود. در این حالت، معادل ناپارامتریک آزمون — یعنی آزمون من-ویتنی (Mann-Whitney U) برای گروههای مستقل یا آزمون ویلکاکسون (Wilcoxon Signed-Rank) برای دادههای زوجی — گزینهی بهتری است.
متغیر شما رتبهای یا اسمی است:
آزمون t فقط برای دادههای کمّی طراحی شده؛ اگر متغیرتان مثلاً سطح رضایت (کم/متوسط/زیاد) یا یک متغیر دوحالتی اسمی است، باید از آزمونهای غیرپارامتریک یا آزمونهای مرتبط با دادههای دستهای (مثل کایاسکوئر) استفاده کنید.
وابستگی نادرست بین دادهها:
اگر دادههای دو گروه در واقع به هم مرتبطاند (مثلاً اندازهگیری تکراری از یک فرد) اما شما آنها را بهاشتباه با آزمون t مستقل تحلیل کنید، نتیجه نادرست خواهد بود؛ در این موارد باید آزمون t زوجی یا روشهای اندازهگیری مکرر را به کار ببرید.
بهطور کلی، پیش از اجرای هر آزمون t، بهتر است نوع داده، تعداد گروهها و نرمال بودن توزیع را بررسی کنید تا انتخاب درستی داشته باشید.
آزمون t فقط وقتی قابل اتکاست که دادهها شرایط لازم را داشته باشند. اگر این شرایط برقرار نباشد، باید به سراغ آزمونهای دیگری رفت. این همان بخشی است که خیلی از پژوهشگران در آن دچار تردید میشوند؛ اینکه دقیقاً کدام آزمون برای دادههایشان مناسبتر است.
در مایند استور، کلیه خدمات آماری از انتخاب آزمون و تحلیل دادهها تا تفسیر خروجی SPSS و مشاوره آماری ارائه میشود تا این مسیر برای شما سادهتر و مطمئنتر پیش برود.
سفارش خدمات آماری
مثالهای کاربردی
مثال ۱: آزمون t تکنمونهای
یک پژوهشگر میخواهد بداند آیا میانگین ساعت مطالعهی روزانهی ۴۰ دانشجوی یک دانشگاه (با میانگین نمونه ۲.۸ ساعت) با میانگین کشوری ۲.۵ ساعت تفاوت دارد یا نه. نتیجهی فرضی: p=0/042, t(39)= 2/10 چون p کمتر از ۰.۰۵ است، میتوان نتیجه گرفت میانگین ساعت مطالعهی این دانشجویان بهطور معناداری بیشتر از میانگین کشوری است.
مثال ۲: آزمون t مستقل
در یک پژوهش، میانگین اضطراب امتحان در ۳۰ دانشآموز دختر (میانگین = ۲۲.۴) و ۳۰ دانشآموز پسر (میانگین = ۱۸.۹) مقایسه شده است. نتیجهی فرضی: : t(58) = 2.85، p = 0.006، با Levene's Test غیرمعنادار (یعنی واریانسها برابر فرض شدهاند). چون p کمتر از ۰.۰۵ است، تفاوت معناداری بین اضطراب دختران و پسران وجود دارد و دختران اضطراب بیشتری گزارش کردهاند.
مثال ۳: آزمون t زوجی
در یک کارگاه آموزشی، نمرهی ۲۵ شرکتکننده قبل (میانگین = ۱۲.۳) و بعد از دوره (میانگین = ۱۶.۸) سنجیده شده است. نتیجهی فرضی: t(24) = 5.42، p < 0.001. این نتیجه نشان میدهد دورهی آموزشی تأثیر معناداری در افزایش نمرهی شرکتکنندگان داشته است.
مثال ۴: تفسیر یک نتیجهی غیرمعنادار
گاهی نتیجهی آزمون t معنادار نیست و این هم یک یافتهی ارزشمند است. مثلاً اگر در مقایسهی میانگین رضایت شغلی بین دو شعبهی یک شرکت به نتیجهی t(48) = 0.87، p = 0.39 برسید، یعنی شواهد کافی برای ادعای تفاوت بین دو شعبه وجود ندارد و باید در متن پایاننامه بنویسید «تفاوت معناداری مشاهده نشد«.
اشتباهات رایج در استفاده از آزمون t
با وجود سادگی ظاهری آزمون t، بسیاری از دانشجویان در اجرا یا تفسیر آن دچار اشتباهات رایج زیر میشوند:
- استفاده از آزمون t برای بیش از دو گروه:
بهجای اجرای چند آزمون t پشتسرهم، باید از ANOVA استفاده کرد.
- نادیده گرفتن نتیجهی آزمونLevene :
خیلیها همیشه ردیف «Equal variances assumed» را گزارش میکنند، بدون اینکه واقعاً نتیجهی Levene را بررسی کنند.
استفاده از آزمون t مستقل برای دادههای وابسته (یا برعکس):
این اشتباه باعث میشود نتیجهی آزمون کاملاً نادرست باشد.
توجه فقط به p-value و نادیده گرفتن اندازه اثر:
یک نتیجهی معنادار از نظر آماری، همیشه به معنای اهمیت عملی بالا نیست.
اجرای آزمون t روی دادههای بهشدت غیرنرمال با حجم نمونهی کم:
در این شرایط باید به سراغ آزمونهای ناپارامتریک رفت.
گزارشنویسی ناقص:
بسیاری فقط p-value را گزارش میکنند و مقدار t، df و اندازه اثر را در متن نمیآورند، در حالی که استانداردهای APA و Vancouver معمولاً همهی این موارد را میخواهند.
تفسیر اشتباه «معنادار نبودن» بهعنوان «هیچ تفاوتی وجود ندارد»:
عدم معناداری آماری فقط به این معناست که شواهد کافی برای رد فرض صفر نداشتیم، نه اینکه تفاوت واقعاً صفر است.
وارد کردن اشتباه کدهای متغیر گروهبندی درSPSS :
اگر کدهای گروهها (مثل ۱ و ۲) بهدرستی در Define Groups وارد نشوند، خروجی کاملاً نادرست خواهد بود.
آزمون t یکی از پایهایترین و پرکاربردترین ابزارهای آمار استنباطی برای مقایسهی میانگینها است. در یک نگاه کلی:
- اگر یک گروه دارید و میخواهید آن را با یک عدد ثابت مقایسه کنید: آزمون t تکنمونهای
- اگر دو گروه کاملاً مستقل دارید: آزمون t مستقل )و حتماً به نتیجهی Levene توجه کنید.(
- اگر دو اندازهگیری مرتبط از یک گروه دارید (مثل قبل/بعد) :آزمون t زوجی
پیش از اجرای هر آزمون t، حتماً پیشفرضهای نرمال بودن، مستقل بودن مشاهدات و (در حالت مستقل) همگنی واریانسها را بررسی کنید و در گزارش نهایی، هم p-value و هم اندازه اثر) d کوهن (را بیاورید.
نکتهی طلایی:
اگر دادههای شما با مفروضههای آزمون t همخوانی نداشته باشد، استفاده از این آزمون میتواند نتیجهای گمراهکننده به همراه داشته باشد. در این شرایط، مهمترین کار این است که روش تحلیل متناسب با دادهها انتخاب شود.
اگر درگیر تحلیل آماری پایاننامه، مقاله یا دادههای پژوهشی هستید و نمیخواهید در انتخاب آزمون یا تفسیر نتایج دچار خطا شوید، تیم مایند استور میتواند این بخش را بهصورت تخصصی برای شما انجام دهد.
سوالات متداول
تفاوت آزمون t و ANOVA چیست؟
آزمون t برای مقایسهی میانگین فقط دو گروه استفاده میشود، در حالی که ANOVA برای مقایسهی میانگین سه گروه یا بیشتر طراحی شده است.
حداقل حجم نمونه برای آزمون t چقدر است؟
هیچ عدد قطعی وجود ندارد، اما معمولاً حداقل ۱۵ تا ۲۰ نفر در هر گروه توصیه میشود؛ هرچه حجم نمونه کمتر باشد، رعایت پیشفرض نرمال بودن اهمیت بیشتری پیدا میکند.
اگر دادههایم نرمال نباشند چه باید کنم؟
در این حالت باید به سراغ معادل ناپارامتریک آزمون t بروید: آزمون من-ویتنی برای گروههای مستقل یا آزمون ویلکاکسون برای دادههای زوجی.
تفاوت آزمون t مستقل و زوجی در یک جمله چیست؟
آزمون t مستقل دو گروه کاملاً جدا از هم را مقایسه میکند، اما آزمون t زوجی دو اندازهگیری مرتبط (معمولاً از همان افراد) را مقایسه میکند.
آیا آزمون t برای دادههای رتبهای هم قابل استفاده است؟
بهطور کلی نه؛ آزمون t برای دادههای کمّی (فاصلهای یا نسبتی) طراحی شده و برای دادههای رتبهای باید از آزمونهای ناپارامتریک استفاده کرد.
تفاوت آزمون t و z-test چیست؟
وقتی واریانس جامعه نامعلوم است و حجم نمونه کوچک است، از آزمون t استفاده میشود؛ z-test معمولاً زمانی به کار میرود که واریانس جامعه مشخص باشد یا حجم نمونه بسیار بزرگ باشد.
چرا باید اندازه اثر را هم گزارش کنم، نه فقط p-value؟
چون p-value فقط معناداری آماری را نشان میدهد و به حجم نمونه حساس است؛ اندازه اثرمثل d (کوهن) نشان میدهد این تفاوت از نظر عملی چقدر بزرگ و قابلتوجه است.





